GIST에서 공개하는 청년 AI. Big Data 아카데미 온라인 기초과정 빅데이터 분석과 R프로그래밍 강의를 참고하였다.
R Studio를 실행하여 실습을 해본다.
|
1
2
3
4
5
|
car<-read.table(file="autompg.txt", na=" ", header=TRUE)
head(car)
dim(car)
str(car)
summary(car)
|
cs |

autompg.txt 파일을 읽어서 car 데이터로 생성하였다. head 함수로 데이터 6개의 출력을 확인하였고, dim 함수로 데이터가 398개의 관측치에 9개의 변수로 이루어진 것을 확인하였다.
str(데이터 이름)
관측치수, 변수들이 저장된 형태등을 파악할 수 있다. mpg, disp, hp, accler는 numeric으로, cyl, wt, year, origin는 int로 carname은 범주형 변수로 저장되어 있는 것을 확인할 수 있다.
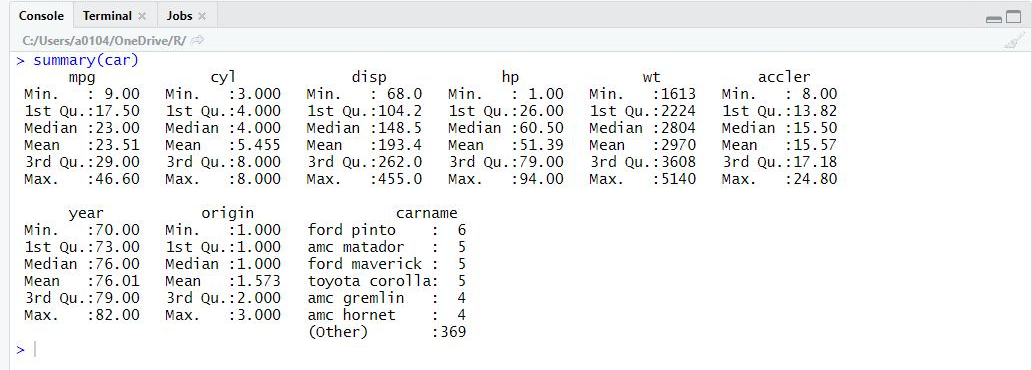
summary 함수로 각 변수별로 최소값, 25% 중간값 평균 75% 최대값을 확인할 수 있고, carname같은 범주형 변수는 빈도수를 출력하여 ford pinto 차 이름이 가장 많이 나온 것을 볼 수 있다.
|
1
2
3
4
5
6
7
|
attach(car)
table(origin)
table(year)
mean(mpg)
mean(hp)
mean(wt)
apply (car[, 1:6], 2, mean)
|
cs |

table(데이터 이름)
데이터의 요약 통계치, 빈도를 구할 수 있다.
table(origin)으로 origin의 빈도수를 확인하였더니 1이 가장 많이 나온 것이 확인된다.
table(year)을 사용하면 70년부터 82년가지 분포된 것을 확인할 수 있다.
apply(변수리수트, (1=row, 2=col), FUN)
평균을 확인하기 위해서는 mean 함수를 사용하여 하나씩 mpg, hp, wt의 평균을 확인할 수 있지만 여러개의 변수의 평균이나 표준편차를 한번에 구하기 위해서는 apply 함수를 사용한다.
apply(car[, 1:6], 2, mean): car 데이터의 변수를 첫번째~여섯번째 변수까지 그 평균을 출력한다.
|
1
2
3
4
|
freq_cyl<-table(cyl)
names(freq_cyl) <- c ("3cyl", "4cyl", "5cyl", "6cyl", "8cyl")
barplot(freq_cyl, main="Cylinders Distribution")
hist(mpg, main="Mile per gallon:1970-1982", col="lightblue")
|
cs |
barplot(데이터 빈도수)
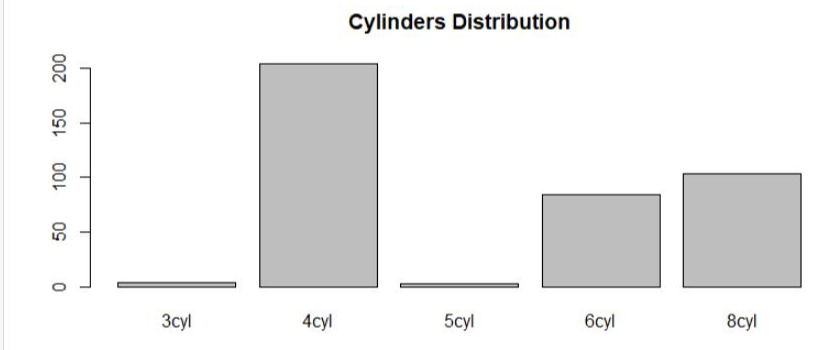
freq_cyl<-table(cyl): cyl의 데이터 요약 통계치를 freq_cyl로 생성하였다.
names(freq_cyl): names로 통계치에 이름을 부여하였다.
barplot(freq_cyl, main="Cylinders Distribution"): freq_cyl 데이터로 막대그래프를 생성한다. main으로 제목을 붙인다.
hist(데이터 이름)

hist(mpg, main="Mile per gallon:1970-1982", col="lightblue"): mpg데이터로 히스토그램을 생성한다. main으로 제목을 붙이고, col옵션으로 색깔은 lightblue로 한다.
scatterplot3d
|
1
2
3
4
|
# install.packages("scatterplot3d")
library(scatterplot3d)
scatterplot3d(wt,hp,mpg, type="h", highlight.3d=TRUE,
angle=55, scale.y=0.7, pch=16, main="3dimensional plot for autompg data")
|
cs |

scatterplot3d는 별도의 패키지 설치가 필요하다. 이전에 설치를 했다면 다시 설치할 필요는 없고, 라이브러리 선언을 해주어야한다.
wt, hp, mpg 세가지 변수로 3d 산점도를 그려준다.
벡터화 요약치 lapply(변수리스트, FUN)
|
1
2
3
4
5
6
7
|
a1<-lapply (car[, 1:6], mean)
a2<-lapply (car[, 1:6], sd)
a3<-lapply (car[, 1:6], min)
a4<-lapply (car[, 1:6], max)
table1<-cbind(a1,a2,a3,a4)
colnames(table1) <- c("mean", "sd", "min", "max")
table1
|
cs |

각 변수들의 평균, 표준편차, 최소값, 최대값을 한꺼번에 볼 수 있다. lapply로 생성한 4개의 값들을 데이터로 만들어서 cbind로 컬럼으로 합친다. colnames로 각 변수의 역할에 맞는 이름을 부여하고 이를 테이블로 만들어서 출력한다.
'R Programming' 카테고리의 다른 글
| [R Programming] R 데이터 활용1 (subset, 내보내기) - Week 3-2 (0) | 2019.09.08 |
|---|---|
| [R Programming] R 데이터 생성 (불러들이기) - Week 3-1 (0) | 2019.09.07 |
| [R Programming] 간단한 함수생성 및 루프(for, while) - Week 2-4 (0) | 2019.09.06 |
| [R Programming] 벡터와 행렬의 연산 - Week 2-3 (0) | 2019.09.05 |
| [R Programming] 객체 이름 정의와 데이터 프레임 - Week 2-2 (0) | 2019.09.04 |



