GIST에서 공개하는 청년 AI. Big Data 아카데미 온라인 기초과정 빅데이터 분석과 R프로그래밍 강의를 참고하였다.
R Studio를 실행하여 실습을 해본다.
벡터에 이름 주기
|
1
2
3
|
gender<-c(0,1)
names(gender)<-c("female", "male")
gender
|
cs |

0,1 값을 갖는 벡터에 0=female 1=male이라는 값을 부여한다.
범주형 변수 생성: factor
|
1
2
|
size<-c("S", "M","L","XL")
size_factor<-factor(size)
|
cs |

|
1
2
|
size_factor2 <- factor(size,levels = c("S", "M","L","XL"))
size_factor2
|
cs |

size벡터는 문자를 가진 단순한 벡터이지만 factor 함수로 범주형 변수로 정의할 수 있다.
is.factor(size_factor): 생성한 size_factor 벡터가 범주형 변수인지를 확인하기 위해서 is.factor 함수를 사용하여 보았더니 참이라는 결과가 나왔다.
size_factor은 순서가 정의 되어있지 않다. S, M, L, XL의 순서를 정의해본다.
|
1
2
|
size_factor3 <- factor(size, ordered = TRUE, levels = c("S", "M","L","XL"))
size_factor3
|
cs |

size_factor3는 ordered = TRUE(순서가 있도록) levels을 정의하여 factor를 생성하였다.
size_factor3의 Level을 보면 S, M, L, XL의 순서를 보여준다.
행렬에 이름주기 dimnames, colnames, rownames
|
1
2
3
|
x<-matrix(rnorm(12),nrow=4)
x
dim(x)
|
cs |

x는 12개의 객체를 랜덤으로 뽑아서 생성한 정규분포 벡터이다. (평균=0, 표준편자=1)
dim(x): dim함수를 이용하여 차원을 알아볼 수 있다. (4x3)
[,1] [,2] [1,] [2,] 와 같이 보기 행렬의 어려운 이름을 다른 이름으로 부여하여 보기 쉽게 하겠다.
|
1
2
3
4
5
|
dimnames(x)[[2]]<-paste("x",1:3,sep="")
x
y<-matrix(rnorm(12),nrow=4)
colnames(y) <- c("y1", "y2", "y3")
y
|
cs |

dimnames(x)[[2]]<-paste("x",1:3,sep=""): x라는 기호에 1부터 3까지 부여하여 열에 이름을 부여한다.
( [[1]]은 행을 의미하고, [[2]]는 열을 의미한다.)
colnames를 사용하여 dimnames와 같이 열에 이름을 부여할 수 있다.
|
1
2
3
4
|
dimnames(x)[[1]]<-paste("id",1:4,sep="")
x
rownames(y) <- c("id1", "id2", "id3","id4")
y
|
cs |

dimnames(x)[[1]]<-paste("id",1:4,sep=""): id라는 기호에 1부터 4까지 부여하여 행에 이름을 부여한다. colnames와 마찬가지로 rownames로 행에 이름을 부여할 수 있다.
행렬과 데이터 프레임
| 데이터프레임은 객체값들을 행렬로 저장할 뿐 아니라 변수명, 관측치번호 등 여러가지 정보를 가지는 객체 이다. |
R에서는 분석할 데이터라면 데이터 프레임으로 정의해주어야 한다.
그러기 위해서는 데이터 프레임이 맞는지 확인할 수 있어야 한다.
|
1
2
3
|
is.data.frame(x)
x<-as.data.frame(x)
is.data.frame(x)
|
cs |

is.data.frame 함수로 데이터 프레임인지 확인할 수 있다.
데이터 프레임으로 인식하게하고 싶다면 as.data.frame으로 정의해줄 수 있다.
x<-as.data.frame(x): x를 데이터 프레임으로 정의하였다.
이제 is.data.frame 함수로 데이터 프레임인지 확인하면 참이 나온다.
|
1
2
3
4
|
x$x1
mean(x$x1)
sd(x$x1)
summary(x)
|
cs |
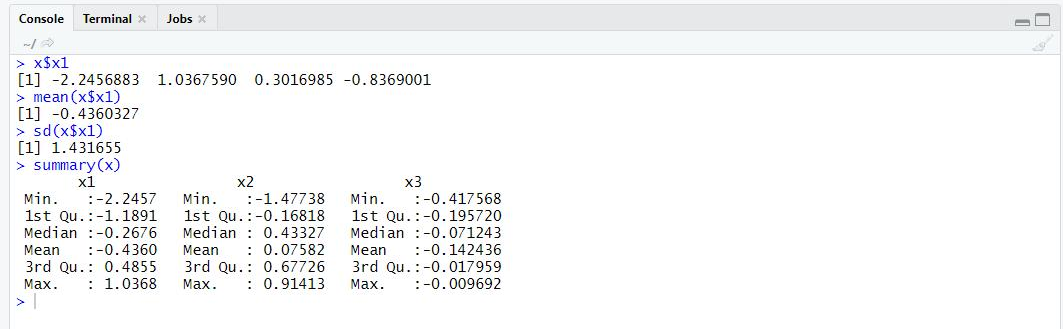
x$x1: x데이터에서 x1변수 값들을 출력한다.
mean(x$x1): x데이터에서 x1변수 값들의 평균을 출력한다.
sd(x$x1): x데이터에서 x1변수 값들의 표준편차를 출력한다.
summary(x): x 데이터 전체의 요약 통계량을 보여준다.
(x1, x2, x3 변수의 최소값, 1/4값, 중간값, 평균값, 3/4값, 최대값)
'R Programming' 카테고리의 다른 글
| [R Programming] 간단한 함수생성 및 루프(for, while) - Week 2-4 (0) | 2019.09.06 |
|---|---|
| [R Programming] 벡터와 행렬의 연산 - Week 2-3 (0) | 2019.09.05 |
| [R Programming] 벡터 및 행렬 생성 - Week 2-1 (0) | 2019.09.03 |
| [R Programming] R 추가 패키지 사용 - Week 1-4 (0) | 2019.09.02 |
| [R Programming] 기본 스크립트와 함수 - Week 1-3 (0) | 2019.09.01 |



